List of Figures
- 3.1. XMLObjApp
- 3.2. XMLObjApp Class Menu
- 3.3. Defining Named Attributes
- 3.4. Family Tree
- 3.5. Family Tree Configuration
- 3.6. Engineer class Configuration
- 3.7. #PCDATA Pseudo-tag Configuration
- 3.8. Parsing HTML Within XML
- 3.9. Success
- 3.10. Failure
- 4.1. Parent class Configuration
List of Examples
- 1.1. Sample Addressbook XML
- 1.2. Decoding XML with XMLObject
- 1.3. Decoding XML with xml.dom
- 1.4. Decoding XML with pyRXP
- 1.5. Decoding XML with xml.sax
- 3.1. Sample Location XML
- 3.2. Exploring _parent and _root
- 3.3. Family Tree XML
- 3.4. Accessing Elements with ReferenceID
- 3.5. Engineer XML
- 3.6. HTML Embedded in XML
- 4.1. Parent class Parser - 1
- 4.2. Parent class Parser - 2
- 4.3. Addressbook and Simpler Parser
- 4.4. AddressBook Parser with __repr__ Additions
- 5.1. Copied from
- 5.2. Multiple UniqueIDs
- 5.3. Searching a Stack Instance
Table of Contents
XMLObject is a Python module that simplifies the handling of XML streams by converting the data into objects.
There are several ways to manipulate XML in Python.
xml.sax is an industry-standard interface, but as such, it does not take advantage of any of the things that really make Python worth using as a programming language. xml.sax lets you define handler functions which it will call while parsing an XML file, but you have to create your own code to actually turn the incoming events into a coherent Python structure.
xml.dom is another industry-standard interface. xml.dom takes care of parsing the entire XML file into a single hierarchy of objects, but the accessor methods are again pretty clumsy. Parsing a file with xml.dom is pretty simple, but the cost is in code overhead of actually using the parsed data.
pyRXP is a blazingly-fast, validating, XML parser. pyRXP parses an XML file into a tuple of tuples, which is easier to traverse than the output of xml.dom, but the resulting code to handle a tuple of tuples isn't particularly readible or easy to maintain.
XMLObject easily parses an XML file and allows you to manipulate it in memory in an intuitive and easy-to-read manner. To compare, let's parse the following XML with XMLObject, xml.dom, pyRXP, and xml.sax:
Example 1.1. Sample Addressbook XML
<AddressBook>
<User ID="1">
<Nickname>Gre7g</Nickname>
<Email>gre7g@wolfhome.com</Email>
<Address>2235 West Sunnyside Dr.</Address>
<City>Cedar City</City>
<State>MT</State>
<Zip>74720</Zip>
</User>
<User ID="2">
<Nickname>Jimbo</Nickname>
<BestFriend ID="1" />
<Email>jimbo@hotmail.com</Email>
<Address>115 North Main</Address>
<Address>Apartment #309</Address>
<City>Columbia</City>
<State>MO</State>
<Zip>65201</Zip>
</User>
</AddressBook>
In this simple address book, each user is indexed by a unique identifier ID. Let's parse the XML with XMLObject, and print out the e-mail address for the user who has ID=2.
Example 1.2. Decoding XML with XMLObject
>>> import XMLObject, AddressBook
>>> Book = XMLObject.Parse("AddressBook.xml", "AddressBook",
... AddressBook.AddressBook)
>>> Book.User["2"].Email
u'jimbo@hotmail.com'
Not only is the e-mail address easy to find, the Python code to find it is simple to read – and will therefore be easy to maintain. Let's compare this with xml.dom code that accomplishes the same task.
Example 1.3. Decoding XML with xml.dom
>>> from xml.dom import minidom
>>> Book = minidom.parse("AddressBook.xml")
>>> Users = Book.getElementsByTagName("User")
>>> User = filter(lambda Node:
... Node.attributes["ID"].value == "2", Users)[0]
>>> User.getElementsByTagName("Email")[0].firstChild.data
u'jimbo@hotmail.com'
It takes a little less code to parse the XML file with xml.dom, but look at how many hoops we have to jump through to find some text data that is only a couple layers down from the top of the structure. The built-in function filter does a great job of finding the correct user, but it does hurt the code's legibility. A for loop would be more readible, but it would take another few lines of code.
Now let's find the e-mail address with pyRXP.
Example 1.4. Decoding XML with pyRXP
>>> from types import *
>>> import pyRXP
>>> AddressBook = open("AddressBook.xml").read()
>>> Book = pyRXP.Parser()(AddressBook)
>>> Users = filter(lambda Node: type(Node) == TupleType,
... Book[2])
>>> User = filter(lambda Node: Node[1]["ID"] == "2",
... Users)[0]
>>> Children = filter(lambda Node: type(Node) == TupleType,
... User[2])
>>> filter(lambda Node: Node[0] == "Email",
... Children)[0][2][0]
'jimbo@hotmail.com'
I love pyRXP's power and speed, but yuck! Three lambda functions and eight references to a constant index do not make for readible code!
Decoding XML with xml.sax is no small undertaking. I'll save you all the editorial comments and allow the code to speak for itself:
Example 1.5. Decoding XML with xml.sax
from types import *
from xml import sax
class cAddressBook(DictType):
pass
class cUser:
pass
class cMyParser(sax.ContentHandler):
def __init__(self):
self.Stack, DOM = [], None
def startElement(self, Name, Attrs):
if Name == "AddressBook":
self.Stack.append(cAddressBook())
elif Name == "User":
User = cUser()
self.Stack[-1][Attrs["ID"]] = User
self.Stack.append(User)
else:
self.Stack.append(Name)
def characters(self, Content):
if Content.strip(): setattr(self.Stack[-2], self.Stack[-1], Content)
def endElement(self, Name):
X = self.Stack.pop()
if not self.Stack: self.DOM = X
def Main():
Parser = cMyParser()
File = open("AddressBook.xml")
sax.parse(File, Parser)
print Parser.DOM["2"].Email
if __name__ == "__main__": Main()
Although XMLObject is flexible and easy-to-use, it is no Swiss army knife. Read through the following list of questions to get better idea of when and when not to use XMLObject.
- 1. Is XMLObject one of those drop-in-and-go programs?
- 2. Can I use XMLObject to parse HTML or other arbitrary documents?
- 3. I need a validating parser. Can XMLObject help me?
- 4. My application is speed-critical. Is XMLObject fast enough?
- 5. Some of the nodes in my XML hierarchy have unique identifiers. Can I manipulate these nodes easily with XMLObject?
I feel that XMLObject has the potential to do far more than it currently does. Here is a list of features I plan to support.
Please contact me by e-mail if you have things to add to this list.
Table of Contents
Releases and/or patches of XMLObject can be found on SourceForge's Project Filelist.
XMLObject is a project in two parts. The XMLObject module is used at run-time to parse XML files. The XMLObjApp application gives you the programmer an easy and convenient way to create parsers for the XML files you will need to parse.
This may sound a bit confusing, but keep reading. It will all make sense. The important thing to note at this point is that you will need both the module and the application while writing your code, but once your coding is complete, you will only need the XMLObject module. If you are creating a distribution, only the XMLObject module need be included, not the XMLObjApp application.
XMLObject may be installed from source or, for Windows users, with a binary installer.
XMLObjApp may be installed from source or, for Windows users, with a binary installer.
- Source install:
To run the source version of XMLObjApp, you will need to have wxPython installed.
$ cd XMLObj/XMLObjApp $ pythonw XMLObjApp.pyw
Note
XMLObjApp has not yet been tested in Linux. Please contact the program author about the state of this debug.- Binary install (Windows):
Simply double-click on XMLObjApp-X.X.setup.exe and follow the on-screen guide. This will install the application on the start menu, and optionally, on the desktop.
Table of Contents
XML can be used to represent almost any kind of data you can imagine. So before XMLObject can translate your XML into Python objects, you need to "teach" it the XML structure to expect and how you would like to access that data. This is done by creating a parser specifically tailored to your XML.
Sound tough? Don't worry. This project includes a program called XMLObjApp which will create the parser code for you.
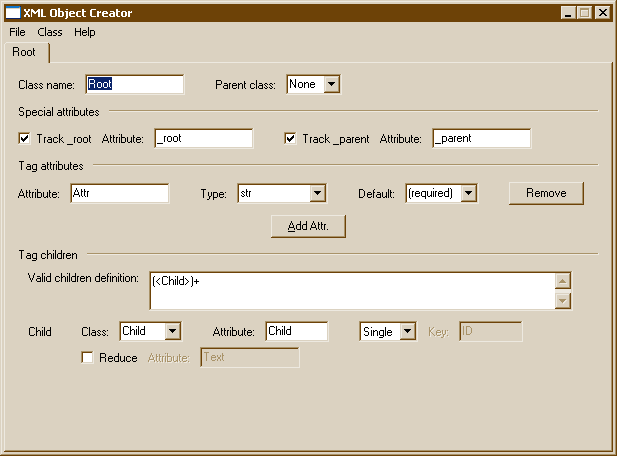
The application is laid out in a fairly straight-forward manner. Each notebook tab across the top represents one class that the parser may instantiate. Typically, each type of tag that might appear in your XML file will get its own class, and therefore, its own notebook tab. Clicking on a tab will bring you to the definition for that class.
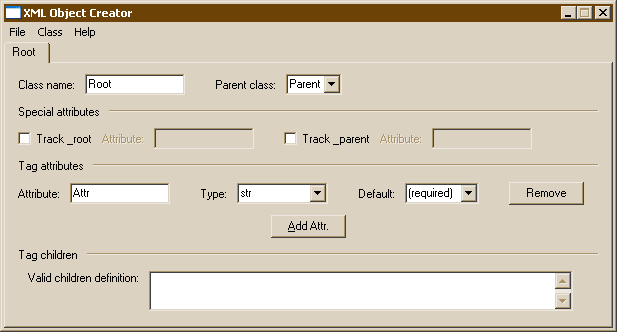
The class name and type are defined at the top of the notebook page.
Special attributes are defined in the next section of the notebook page.
The middle region allows you to define which XML attributes may appear for the given tag.
The bottom region allows you to specify which children the tag may have. The syntax is akin to a regular expression.
When you first run the XMLObjApp, the application will construct a simple class called Root to get you started. Your top-most class does not have to be called Root. In fact, the best name for this class is simply the tag name itself, or "AddressBook" in our example.
Use -> (Ctrl-N) to create a class for each type of tag that can appear in your XML file. -> deletes the current class, but be careful! There is no undo.
Directly beneath the notebook tabs are form fields for the class name and an optional parent class name. The class name must be unique and a valid Python identifier, so don't include any punctuation in the class name.
If you wish to derive the class from another class, you may enter the parent class name in the appropriate field. Don't worry about defining the parent class just yet. We can do that later by editing the parser source code.
Each class may include two optional, special attributes. By default, these are called _parent and _root. The _parent attribute provides access to the parent tag instance and the _root attribute provides access to the root of the XML structure.
Let's illustrate this relationship with a very simple piece of XML which describes my home town:
Example 3.1. Sample Location XML
<Country Name="USA">
<State Name="Missouri">
<City Name="Columbia" />
</State>
</Country>
In the above example, the City object's _parent attribute refers to the State object. The City object's _root attribute refers to the Country object.
Let's explore this with a little code:
Example 3.2. Exploring _parent and _root
>>> import XMLObject, city
>>> Country = XMLObject.Parse("city.xml", "Country",
... city.Country)
>>> Country.Name
'USA'
>>> Country.State.Name
'Missouri'
>>> Country.State.City.Name
'Columbia'
>>> Country.State.City._parent.Name
'Missouri'
>>> Country.State.City._root.Name
'USA'
XML elements can convey data in two distinct ways: named attributes within the XML tag, and child data (string data or additional XML tags) between the element's open and close tags.
Named attributes should be added in XMLObjApp's middle section by clicking the button. Add one entry for each named attribute that can appear within the given tag. Attributes may be removed with the button, but be careful! There is no undo.
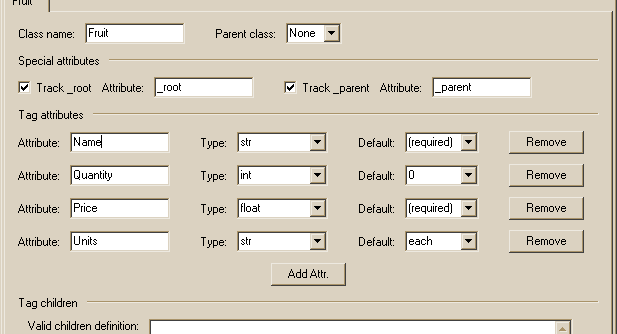
Select an appropriate type and default for each attribute. A variety of types are provided in the pull-down, but you can also enter your own function or class by typing the name in the combo-box. See Manually Editing Your Parser for more on entering your own code.
If an attributes does not have a default value, you can pull down values of (required) or None. Choosing (required) will require the attribute to be present in the tag, or else a TypeError exception will be thrown during the parsing process.
The above example will parse the XML tag
<Fruit Name="oranges" Quantity="10" Price="0.59" Units="per pound">
into the following object:
Obj = Fruit()
Obj.Name = "oranges"
Obj.Quantity = 10
Obj.Price = 0.59
Obj.Units = "per pound"
Note
Named attributes are always saved as object members of the same name.
XMLObj provides two special types for dealing with unique identifiers – UniqueID to hold them and ReferenceID to cross-reference them.
Suppose you wanted to represent a set of objects that don't fit cleanly into XML's single-parent/multiple-children hierarchy:
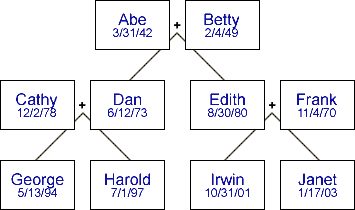
You could do it with the following XML:
Example 3.3. Family Tree XML
<Family>
<Member Name="Abe" DOB="3/31/42" />
<Member Name="Betty" DOB="2/4/49" />
<Member Name="Cathy" DOB="12/2/78" />
<Member Name="Dan" Father="Abe" Mother="Betty" DOB="6/12/73" />
<Member Name="Edith" Father="Abe" Mother="Betty" DOB="8/30/80" />
<Member Name="Frank" DOB="11/4/70" />
<Member Name="George" Father="Dan" Mother="Cathy" DOB="5/13/94" />
<Member Name="Harold" Father="Dan" Mother="Cathy" DOB="7/1/97" />
<Member Name="Irwin" Father="Frank" Mother="Edith" DOB="10/31/01" />
<Member Name="Janet" Father="Frank" Mother="Edith" DOB="1/17/03" />
</Family>
By configuring the Name attribute as a UniqueID type and the Father and Mother attributes as ReferenceID type, we can make it easy to cross-reference between them.
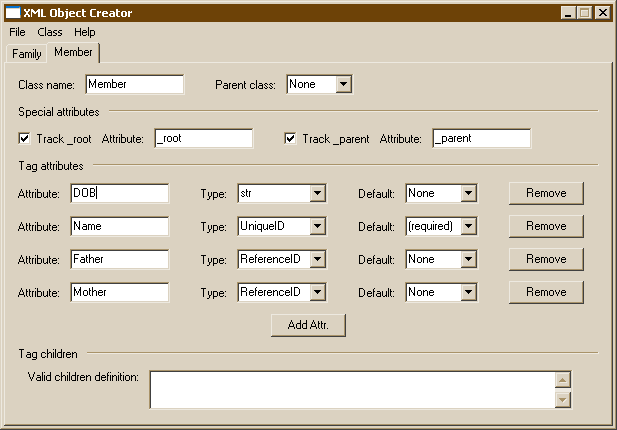
Example 3.4. Accessing Elements with ReferenceID
>>> import XMLObject, tree
>>> Tree = XMLObject.Parse("tree.xml", "Family", tree.Family)
>>> Tree.Member["Janet"].DOB
'1/17/03'
>>> Tree.Member["Janet"].Mother().DOB
'8/30/80'
>>> Tree.Member["Janet"].Mother().Father().DOB
'3/31/42'
Note
Unless you have elements that need to cross-reference to other elements, then there is probably no need to use UniqueID. See ReferenceID.
More information on the use of ReferenceID types may be found in ReferenceID.
Attribute values may be constrained somewhat by selecting the appropriate type and/or by setting an attribute's default to (required). However, this is not always sufficient. Sometimes you need to:
insure that a string attribute is any one value from a finite list of options
insure that a numeric attribute falls within an "acceptable" range
allow a tag to define one attribute or another, but not both
Although XMLObjApp does not let you enter constraints such as these directly, you can constrain XML attributes by manually editing the parser source.
Each class needs a valid children definition (VCD) string to define which tags are allowed as children (a blank VCD indicates that the class is not allowed to have any children). This string looks a lot like a regular expression. It allows the use of parenthesis, braces, modifiers (*, +, and ?), and the | operator just like regular expressions do.
Note
Put all tags or sets of tags in parenthesis before adding modifiers or the | operator to the VCD.
Instead of giving a huge lesson on regular expressions, I'm just going to describe a few sets of allowed children and show you the VCD you could enter to specify such a set. I'm confident that you'll be able to extrapolate from there.
Note
Feel free to put whitespace in your VCD's to make them easier to read.
- One or more <User> tags.
(<User>)+
- Any number of <Foo>, <Bar>, or <Snafu> tags – in any order.
((<Foo>) | (<Bar>) | (<Snafu>))+
- A <Nickname>, possibly a <BestFriend>, an <Email>, one to two <Address> tags, a <City>, a <State>, and a <Zip> – in that order.
<Nickname> (<BestFriend>)? <Email> (<Address>){1,2} <City><State><Zip>
Once you've entered your VCD, hit Tab or click on any other control. As soon as the VCD control loses focus, XMLObjApp will recalculate the list of possible children and add or remove fields to allow you to configure how these children should be processed.
To indicate that a class can have raw text as a child, enter the pseudo-tag #PCDATA into the VCD. The #PCDATA pseudo-tag acts like any other tag.
Note
The #PCDATA pseudo-tag must be entered exactly. Case is signifigant.
On occassion, you may not want XMLObject to parse some of the XML in your stream. You might want all of an element's subordinate XML to be stored raw for later processing. This is accomplished by using the <XML> pseudo-tag.
Notes
The <XML> pseudo-tag must be entered exactly. Case is signifigant.
The <XML> pseudo-tag "consumes" all child tags and/or text between the given element's beginning and ending tags. If present, it should be used exclusively as a class' VCD string, and not mixed in with any other tags, modifiers, or operators.
The <XML> pseudo-tag places very few requirements on the nature of the subordinate XML. The XML must be well balanced (i.e. it must have an appropriately placed closing tag for every opening tag), but that's about it. The XML captured may be empty.
To complete our configuration of a class, we must specify how the children should be attached to the class. There are four fundamental things we need to define for each child:
What class should be instantiated?
What object member name should be used?
How should the data be saved?
Should all of the data be saved, or just a portion?
To illustrate these decisions, let's look at some really contrived XML that describes an engineer:
Example 3.5. Engineer XML
<Engineer Name="Duane">
<Boss Name="Cecil"> (lots of "boss" data) </Boss>
<Spouse>Elizabeth</Spouse>
<Child>Herman</Child>
<Child>Olaf</Child>
<Project ProjCode="210"> (lots of data on project #210) </Project>
<Project ProjCode="229"> (lots of data on project #229) </Project>
<Project ProjCode="766"> (lots of data on project #766) </Project>
</Engineer>
To parse data such as this, I would configure my Engineer class in the following way:
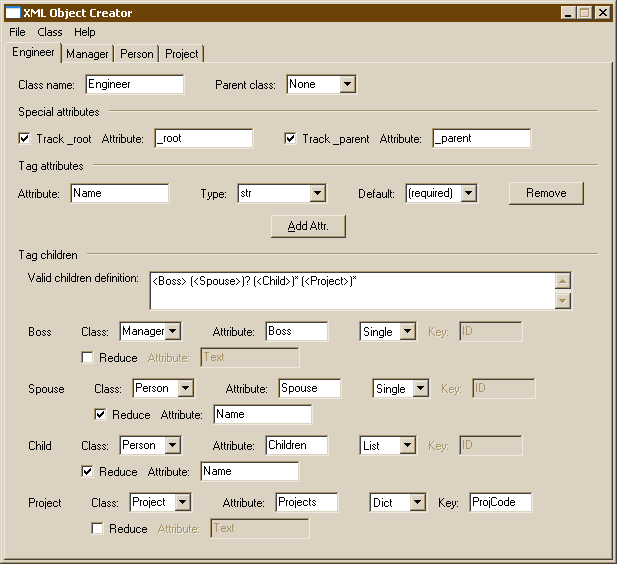
As you can see from the VCD string, we expect a single boss, the possibility of a single spouse (must not be living in Utah!), any number of children (including none), and any number of projects.
The boss will be an instance of class Manager and stored in the Engineer attribute Boss. The boss instance is liable to contain several pieces of information, so we won't reduce it down any.
There can only be one spouse, just as there is only one boss, so we will save this information as attribute Spouse. However, there's only one thing of interest in the Spouse attribute – the Spouse's name.
Since the spouse has only one piece of real data, it's more convenient to access this data as Engineer.Spouse instead of as Engineer.Spouse.Name. To do this reduction, I've checked the appropriate checkbox and entered the Name member into the appropriate field.
Note
When reducing data, the child class is still instantiated. Data reduction takes places after the instantiation and XML element processing.
The engineer may have any number of children. Each <Child> element is very similar in structure to the <Spouse> element. I've taken advantage of this and used the same class for both.
I've configured the Child element capture in much the same way as the <Spouse> element. Each child is reduced to the value of the Name member. The difference is that there can be multiple <Child> elements, but only one <Spouse> element. To handle these multiple elements, I've configured Child to store the data values in a list called Children.
Parsing the Engineer XML above with the model shown, will give Engineer.Children a value of ['Herman', 'Olaf'].
Like the Boss member, the Projects member will not be reduced. Each project will undoubtably contain multiple pieces of useful data we will want to maintain. However, there can be multiple projects, just as there could be multiple children. We could store these in a list, like we did with the children, but because each <Project> has a unique ProjCode, it will probably be a better choice for us to put these projects in a dictionary (with a key of ProjCode).
By putting the projects in a dictionary, we can get a list of project codes with Engineer.Projects.keys(), a list of the projects with Engineer.Projects.values(), or even access a specific project with Engineer.Projects["229"] (for example). This lets us access a specific project without having to search the list for the appropriate list index.
Note
Regardless of the underlying index type, XMLObject always creates string type dictionary keys.
As mentioned previously, elements can have child text. Configuring how the text should be processed and stored begins with entering the #PCDATA pseudo-tag into the VCD. #PCDATA configuration is as shown:
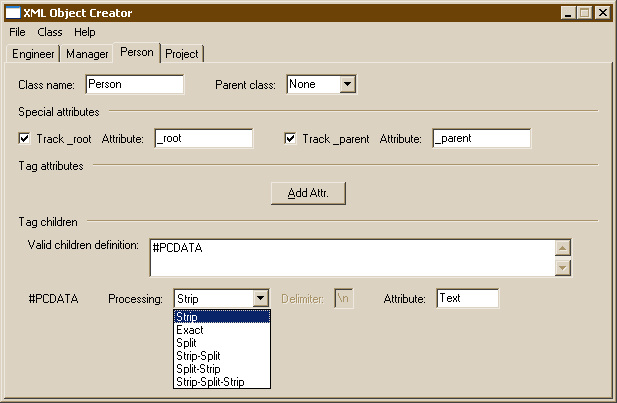
Text may be processed in a variety of ways:
- Strip
White-space is stripped from the beginning and ending of the text.
- Exact
Text is captured exactly. No white-space is stripped.
- Split
Text is split into a list, broken by the given delimiter.
- Strip-Split
White-space is stripped from the beginning and ending of the text. Then, the remaining text is split into a list, broken by the given delimiter.
- Split-Strip
Text is split into a list, broken by the given delimiter. Then, white-space is stripped from the beginning and ending of each list item.
- Split-Strip
White-space is stripped from the beginning and ending of the text. Then, the remaining text is split into a list, broken by the given delimiter. Finally, white-space is stripped from the beginning and ending of each list item.
Regardless of how the text is processed, it is saved as the entered attribute name.
Note
The pseudo-tag #PCDATA will catch multiple lines of text. You do not need to put "(#PCDATA)*" in your VCD to indicate that there may be any amount of text.
However, if the text is optional, you should indicate this by putting a "(#PCDATA)?" in your VCD instead of just "#PCDATA".
As mentioned previously, there are times when you just don't want to parse all the XML in a document. One common situation for this is when one program wants to communicate an HTML-formatted message to another program. Using an <XML> pseudo-tag will accomplish just that.
Could be parsed with:
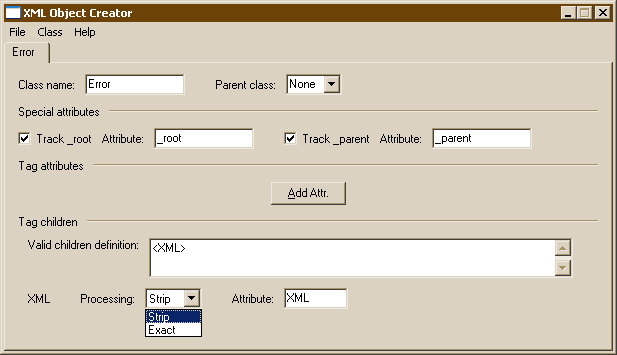
'File could <b>not</b> be opened.'
Alternately, you can choose to extract the text Exactly and not strip off any extraneous white-space.
Note
The pseudo-tag <XML> will catch any and all XML children. You do not need to put "(<XML>)?" or "(<XML>)*" in your VCD to try and indicate what sort of XML to expect.
Likewise, do not mix <XML> with any other tag in your VCD.
XMLObject will not enforce any such restrictions, apart from the XML being well-formed. If the XML must be validated, do so by editing in an _end_init function.
Most of the items on the Menu require very little explaination. -> (Ctrl-O), -> (Ctrl-S), ->, and -> all open, save, and close the current XML parser description as a Python module.
By default, XMLObjApp performs a sanity test before saving the parser file. If the test fails, XMLObjApp will alert you and ask if the file should be saved anyhow. Saving a parser with errors in it is risky as it may not be possible to load the parser later to fix the errors.
You may disable this pre-save test in the preferences.
-> (Ctrl-T) runs a quick check on the parser you have created to make sure it makes sense. It checks for obvious problems, such as putting illegal characters in attribute names and defining a class multiple times, to more subtle mistakes, such as neglecting to define a class you use.
If successful, the will pop up a simple dialog to notify you of success:
On a failure, will open a list of errors and warnings:

The failure messages are pretty self-explanitory, so I won't waste time
detailing each one. Error messages are marked with a  symbol and warnings with a
symbol and warnings with a  symbol. Click on any message link to jump
to the appropriate class page and field that caused the
problem. Errors certainly need to be fixed. Warnings may need to be fixed.
symbol. Click on any message link to jump
to the appropriate class page and field that caused the
problem. Errors certainly need to be fixed. Warnings may need to be fixed.
One of XMLObjApp's more convenient features is the -> menu item. This function imports an XML file and takes some guesses about what sorts of classes, attributes, and children should go into your parser. The configuration will almost certainly not be correct, but it should save you tons of time in creating your parser. Simply import your XML file and then tweak all the settings until they match your file's structure.
Note
By default, -> closes the current parser before importing the XML document. You may change this setting in the preferences.
-> allows you to set all of the following:
- Indention amount:
By default, XMLObjApp indents four spaces whenever creating a subordinate source code block. You may tweak this value here or instruct XMLObjApp to use a single tab character instead.
Changing this setting may have a profound effect on any code you have manually edited into your parser. I strongly recommend you pick a value and stick with it.
- Column wrap:
By default, XMLObjApp wraps source code it generates at column 79. You may tweak this value here.
- Recently used file list:
By default, XMLObjApp remembers the four most recently used parser files and keeps them on your menu for easy access. You may tweak the number of files remembered here.
- Import XML:
By default, XMLObjApp closes the current parser file before importing an XML document. You may also set the application to leave the current parser open (thereby adding new classes to it) or to ask if the current file should be closed before importing an XML document.
- Special attributes:
This section of the preferences dialog allows you to set the default special attributes to use whenever a parser class is created.
- Sanity test:
By default, XMLObjApp performs a sanity test before saving the parser file. If the test fails, XMLObjApp will alert you and ask if the file should be saved anyhow. Saving a parser with errors in it is risky as it may not be possible to load the parser later to fix the errors.
You may disable this pre-save test here.
- Program paths:
XMLObjApp will guess appropriate values for the browser and help program paths. You may customize these values here.
Table of Contents
Keep in mind that XMLObject is a wrapper around your existing xml.sax or pyRXP library. It is not an XML parser.
For this reason, member strings will be the same type as whatever is provided by the underlying parser module. The current version of xml.sax returns unicode strings and the current version of pyRXP returns ASCII strings.
Your code should be prepared for whatever type of string is returned by XMLObject. If your program cannot handle both ASCII and unicode strings, then you should either cast your strings or force XMLObject to use your parser of choice.
XMLObject will try to import pyRXP when it is, itself, imported. If this import fails, XMLObject will resort to using xml.sax. To force XMLObject to use xml.sax regardless of whether pyRXP is available, add the following code after you've imported XMLObject, but before you've called XMLObject's Parse function:
XMLObject.pyRXP = None
Although XMLObject automatically generates a Python parser for you, you may wish to edit the parser to enhance its functionality. One time that you'll certainly want to do this is when you derive the parser classes from other classes.
Consider the painfully simple example:
This will create the following parser:
Example 4.1. Parent class Parser - 1
# vvv Generated code, do not modify vvv
import XMLObject
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class Root(Parent):
ChildSpec = XMLObject.ChildClass({}, "")
def __init__(self, Attr, XMLStack=XMLObject.Stack()):
self.Attr = str(Attr)
# ^^^ Generated code, do not modify ^^^
This code won't load, of course, since we haven't yet defined the Parent class just yet. We can do this by editing the code and either entering the class into the module or by importing it with a:
from ParentModule import Parent
For now, we'll just add code directly into the parser:
Example 4.2. Parent class Parser - 2
# vvv Generated code, do not modify vvv import XMLObject # ^^^ Generated code, do not modify ^^^ class Parent: def __init__(self): self.Var = 5 # vvv Generated code, do not modify vvv class Root(Parent): ChildSpec = XMLObject.ChildClass({}, "") def __init__(self, Attr, XMLStack=XMLObject.Stack()): self.Attr = str(Attr) # ^^^ Generated code, do not modify ^^^ Parent.__init__(self)
Note how I've added the Parent class and the Parent class construction without modifying any code within the blocks marked "do not modify". This is important.
Modifying the code within these blocks can still create valid code, but you may no longer be able to reload the code with XMLObjApp. Worse, the application may load the code, but then save changes to these blocks without any warnings. Just don't do it.
You can also add member functions to classes, as long as the code you add is not within the "do not modify" blocks.
Throughout this document, I've been talking about parsing XML documents into Python objects. I have yet to mention using Python objects to output XML.
The reason for this rather glaring omission is that neither XMLObject nor XMLObjApp contribute to the process. I've tried to figure out a way to automate code generation to output XML, but it is much harder to come up with a generic solution than you might suppose.
So instead of creating some code destined to be eternally buggy, I've decided to reserve this portion of the documentation to illustrate how you can write your own code members to output XML.
Let's parse our earlier addressbook example with a simpler parser.
Example 4.3. Addressbook and Simpler Parser
<AddressBook>
<User ID="1">
<Nickname>Gre7g</Nickname>
<Email>gre7g@wolfhome.com</Email>
<Address>2235 West Sunnyside Dr.</Address>
<City>Cedar City</City>
<State>MT</State>
<Zip>74720</Zip>
</User>
<User ID="2">
<Nickname>Jimbo</Nickname>
<BestFriend ID="1" />
<Email>jimbo@hotmail.com</Email>
<Address>115 North Main</Address>
<Address>Apartment #309</Address>
<City>Columbia</City>
<State>MO</State>
<Zip>65201</Zip>
</User>
</AddressBook>
# vvv Generated code, do not modify vvv
import XMLObject
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class Text:
ChildSpec = XMLObject.ChildClass({"#PCDATA": XMLObject.PCDATAChild("Strip",
"Text")}, "#PCDATA")
def __init__(self, XMLStack=XMLObject.Stack()):
self.Text = ""
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class BestFriend:
ChildSpec = XMLObject.ChildClass({}, "")
def __init__(self, ID, XMLStack=XMLObject.Stack()):
self.ID = XMLStack.ReferenceID(ID, XMLStack)
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class User:
ChildSpec = XMLObject.ChildClass({"Nickname": XMLObject.StdChild(Text,
"Nickname", "Single", Reduce="Text"), "Email": XMLObject.StdChild(
Text, "Email", "Single", Reduce="Text"), "Address": XMLObject.StdChild(
Text, "Address", "List", Reduce="Text"), "City": XMLObject.StdChild(
Text, "City", "Single", Reduce="Text"), "State": XMLObject.StdChild(
Text, "State", "Single", Reduce="Text"), "Zip": XMLObject.StdChild(
Text, "Zip", "Single", Reduce="Text"), "BestFriend": XMLObject.StdChild
(BestFriend, "BestFriend", "Single", Reduce="ID")},
"(<Nickname>)?(<BestFriend>)?(<Email>)?(<Address>)*(<City>)?(<State>)?(<Zip>)?"
)
def __init__(self, ID, XMLStack=XMLObject.Stack()):
self.ID = XMLStack.UniqueID("User", ID, self, XMLStack)
self.Nickname = ""
self.Email = ""
self.Address = []
self.City = ""
self.State = ""
self.Zip = ""
self.BestFriend = ""
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class AddressBook:
ChildSpec = XMLObject.ChildClass({"User": XMLObject.StdChild(User, "User",
"Dict", Key="ID")}, "(<User>)*")
def __init__(self, XMLStack=XMLObject.Stack()):
self.User = {}
# ^^^ Generated code, do not modify ^^^
To output XML, we will need to add a member function to both the AddressBook and User classes. There isn't much point in adding code to either the BestFriend or Text classes because all instances of these classes will be reduced. There will not actually be any instances of these classes in the final, parsed object hierarchy.
You can use most any member function name to output XML, but I prefer __repr__:
Example 4.4. AddressBook Parser with __repr__ Additions
# vvv Generated code, do not modify vvv
import XMLObject
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class Text:
ChildSpec = XMLObject.ChildClass({"#PCDATA": XMLObject.PCDATAChild("Strip",
"Text")}, "#PCDATA")
def __init__(self, XMLStack=XMLObject.Stack()):
self.Text = ""
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class BestFriend:
ChildSpec = XMLObject.ChildClass({}, "")
def __init__(self, ID, XMLStack=XMLObject.Stack()):
self.ID = XMLStack.ReferenceID(ID, XMLStack)
# ^^^ Generated code, do not modify ^^^
# vvv Generated code, do not modify vvv
class User:
ChildSpec = XMLObject.ChildClass({"Nickname": XMLObject.StdChild(Text,
"Nickname", "Single", Reduce="Text"), "Email": XMLObject.StdChild(
Text, "Email", "Single", Reduce="Text"), "Address": XMLObject.StdChild(
Text, "Address", "List", Reduce="Text"), "City": XMLObject.StdChild(
Text, "City", "Single", Reduce="Text"), "State": XMLObject.StdChild(
Text, "State", "Single", Reduce="Text"), "Zip": XMLObject.StdChild(
Text, "Zip", "Single", Reduce="Text"), "BestFriend": XMLObject.StdChild
(BestFriend, "BestFriend", "Single", Reduce="ID")},
"(<Nickname>)?(<BestFriend>)?(<Email>)?(<Address>)*(<City>)?(<State>)?(<Zip>)?"
)
def __init__(self, ID, XMLStack=XMLObject.Stack()):
self.ID = XMLStack.UniqueID("User", ID, self, XMLStack)
self.Nickname = ""
self.Email = ""
self.Address = []
self.City = ""
self.State = ""
self.Zip = ""
self.BestFriend = ""
# ^^^ Generated code, do not modify ^^^
def __repr__(self):
RetVal = '<User ID="%s">' % self.ID
if self.Nickname: RetVal += "<Nickname>%s</Nickname>" % self.Nickname
if self.BestFriend: RetVal += '<BestFriend ID="%s" />' % self.Nickname
if self.Email: RetVal += "<Email>%s</Email>" % self.Email
for Address in self.Address:
RetVal += "<Address>%s</Address>" % Address
if self.City: RetVal += "<City>%s</City>" % self.City
if self.State: RetVal += "<State>%s</State>" % self.State
if self.Zip: RetVal += "<Zip>%s</Zip>" % self.Zip
return RetVal + "</User>"
# vvv Generated code, do not modify vvv
class AddressBook:
ChildSpec = XMLObject.ChildClass({"User": XMLObject.StdChild(User, "User",
"Dict", Key="ID")}, "(<User>)*")
def __init__(self, XMLStack=XMLObject.Stack()):
self.User = {}
# ^^^ Generated code, do not modify ^^^
def __repr__(self):
RetVal = "<AddressBook>"
for User in self.User.values():
RetVal += repr(User)
return RetVal + "</AddressBook>"
>>> import XMLObject, AddressBook2
>>> Book = XMLObject.Parse("AddressBook.xml", "AddressBook",
... AddressBook2.AddressBook)
>>> repr(Book)
'<AddressBook><User ID="1"><Nickname>Gre7g</Nickname><Email>gre7g@wolfhome.com<
/Email><Address>2235 West Sunnyside Dr.</Address><City>Cedar City</City><State>
MT</State><Zip>74720</Zip></User><User ID="2"><Nickname>Jimbo</Nickname><BestFr
iend ID="Jimbo" /><Email>jimbo@hotmail.com</Email><Address>115 North Main</Addr
ess><Address>Apartment #309</Address><City>Columbia</City><State>MO</State><Zip
>65201</Zip></User></AddressBook>'
Table of Contents
This module helps represent XML with a more "natural" set of object instances.
It defines the following members:
- XMLStructError(exception)
XMLStructError is an Exception thrown when an XML file differs from the structure allowed by the parser. exception is a text message describing what went wrong.
- Stack
Stack is a class used to track an element's relationship to the rest of the document. Stack is passed to element constructors during XML parsing.
- ChildClass(Dict, Validator)
ChildClass is a class used to describe what children an element may have. ChildClass is stored in a class member called ChildSpec.
Dict is dictionary mapping of tags to classes that are allowed as children for this particular element. Keys should be text strings such as "Tag", and not a VCD-ish variant such as "<Tag>". Values should be an instance of either PCDATAChild, XMLChild, or StdChild.
Validator is the element's VCD string. See VCD Strings for more information on creating VCD strings.
- PCDATAChild(Processing, Attr[, Delimiter])
PCDATAChild defines how the #PCDATA pseudo-tag should be configured. PCDATAChild instances are stored in the element's ChildSpec.
Processing is a string indicating how the text should be processed. Processing should have one of the following constant values: "Strip", "Exact", "Split", "Strip-Split", "Split-Strip", or "Strip-Split-Strip". See Configuring a #PCDATA Child Type for more information on processing text strings.
Attr is a string indicating which attribute of the class instance should receive the text.
Delimiter is a string used to split text strings into a list. Delimiter is only signifigant if Processing is set to "Split", "Strip-Split", "Split-Strip", or "Strip-Split-Strip".
- XMLChild(Processing, Attr)
XMLChild configures how the <XML> pseudo-tag should be configured. XMLChild instances are stored in the element's ChildSpec.
Processing is a string indicating how the XML should be processed. Processing should either be "Strip" or "Exact".
Attr is a string indicating which attribute of the class instance should receive the XML text.
- StdChild(Class[, Attr][, Save][, Key][, Reduce])
StdChild configures how the standard tags should be configured. StdChild instances are stored in the element's ChildSpec.
Class is the class to instantiate when this child is parsed.
Attr is a string indicating which attribute of the class instance should receive the new instance.
Save is a string indicating how the child should be saved. Save should either be "Single", "List" or "Dict". See Configuring a Typical Child Type for more information on saving children.
Key is the class member used as dictionary key. Key is only signifigant if Save is set to "Dict".
Reduce is the class member to reduce to. No reduction will be done if this member is left unset or is set to None.
- Parse(FilenameOrStream, RootTag, RootClass, [XMLStack])
Parse is a function that parses XML from a file or stream represented by FilenameOrStream and returns the document's root object.
RootTag is a text string representing the expected, top-most tag in the XML file or stream. It should be the name of the tag only, such as "Root", and not a VCD-ish variant such as "<Root>". If the top-most tag is anything other than RootTag, then XMLObject will raise an XMLStructError exception.
RootClass is the class to instantiate for the top-most element in the XML file or stream.
XMLStack is optional. You can create an empty Stack instance yourself and pass it in to Parse as XMLStack. You should only need to do this if you plan to find elements by their UniqueID, and you don't know where in the document hierarchy they will be located. See Example 5.3, “Searching a Stack Instance”.
Stack is a class used to track an element's relationship to the rest of the document. Stack is passed to element constructors during XML parsing.
It defines the following members:
- UniqueID(Class, ID, Obj, Stack)
UniqueID is a class used to implement the UniqueID XML attribute type. UniqueID holds a string type identifier. Access this identifier by casting the UniqueID to a string with the str function.
Note
UniqueIDs are instantiated by the parser. You should not need to instantiate a UniqueID yourself.
Class is the string name of the class in which the UniqueID can be found.
ID is the unique string value assigned to the instance.
Obj is class instance which will hold the identifier, i.e. the object that ReferenceID will want to access, given the associated value of ID.
Stack is the parser Stack. UniqueIDs are actually stored in the Stack object. This allows the ReferenceID object to cross-reference them.
- ReferenceID(ID, Stack)
ReferenceID is a class used to implement the ReferenceID XML attribute type. ReferenceID allows you to cross reference another object with a matching UniqueID attribute.
Note
ReferenceIDs are instantiated by the parser. You should not need to instantiate a ReferenceID yourself.
Note
It is legal to instantiate a ReferenceID with a given value before the corresponding object with a matching UniqueID has been instantiated. A cross-reference search is not actually executed until a look-up is made.
ID is the unique string value assigned to some other object's UniqueID instance.
Stack is the parser Stack. UniqueIDs are actually stored in the Stack object. This allows the ReferenceID object to cross-reference them.
UniqueIDs serve two purposes; they allow elements to cross-reference each other, and they provide a mechanism to find an element by ID – regardless of where the element is located in the document hierarchy.
Example 5.1. Copied from Example 3.3, “Family Tree XML”
ReferenceIDs are called like functions to refer to other elements.
<Family>
<Member Name="Abe" DOB="3/31/42" />
<Member Name="Betty" DOB="2/4/49" />
<Member Name="Cathy" DOB="12/2/78" />
<Member Name="Dan" Father="Abe" Mother="Betty" DOB="6/12/73" />
<Member Name="Edith" Father="Abe" Mother="Betty" DOB="8/30/80" />
<Member Name="Frank" DOB="11/4/70" />
<Member Name="George" Father="Dan" Mother="Cathy" DOB="5/13/94" />
<Member Name="Harold" Father="Dan" Mother="Cathy" DOB="7/1/97" />
<Member Name="Irwin" Father="Frank" Mother="Edith" DOB="10/31/01" />
<Member Name="Janet" Father="Frank" Mother="Edith" DOB="1/17/03" />
</Family>
import XMLObject
class Member:
ChildSpec = XMLObject.ChildClass({}, "")
def __init__(self, Name, DOB=None, Father=None, Mother=None, XMLStack=None):
self.DOB = str(DOB)
self.Name = XMLStack.UniqueID("Member", Name, self, XMLStack)
self.Father = XMLStack.ReferenceID(Father, XMLStack)
self.Mother = XMLStack.ReferenceID(Mother, XMLStack)
class Family:
ChildSpec = XMLObject.ChildClass({"Member": XMLObject.StdChild(Member,
"Member", "Dict", Key="Name")}, "(<Member>)*")
def __init__(self, XMLStack):
self.Member = {}
>>> import XMLObject, tree
>>> Tree = XMLObject.Parse("tree.xml", "Family", tree.Family)
>>> Tree.Member["Janet"].DOB
'1/17/03'
>>> Tree.Member["Janet"].Mother().DOB
'8/30/80'
>>> Tree.Member["Janet"].Mother().Father().DOB
'3/31/42'
Example 5.2. Multiple UniqueIDs
Although effective in the previous example, what happens when you can't guarantee that your UniqueIDs are truly unique?
Suppose you have multiple tag types (<A> and <B>) with unique identifiers. If these identifiers are unique across a single tag type (all <A> UniqueIDs are unique and all <B> UniqueIDs are unique) but it's possible that both tag types may have overlapping identifiers, then you can't simply call a ReferenceID and know you'll get the right tag returned. In such cases, you must specify which tag type a ReferenceID call should return.
To illustrate this, consider the following, painfully-contrived example:
<Elements>
<Fruit Name="apple" Color="red" Size="medium" />
<Fruit Name="orange" Color="orange" Size="medium" />
<Fruit Name="grape" Color="purple" Size="small" />
<Color Name="red" Fruit="apple" />
<Color Name="orange" Fruit="orange" />
<Color Name="purple" Fruit="grape" />
</Elements>
import XMLObject
class Fruit:
ChildSpec = XMLObject.ChildClass({}, "")
def __init__(self, Name, Color=None, Size=None, XMLStack=None):
self.Name = XMLStack.UniqueID("Fruit", Name, self, XMLStack)
self.Color = XMLStack.ReferenceID(Color, XMLStack)
self.Size = Size
class Color:
ChildSpec = XMLObject.ChildClass({}, "")
def __init__(self, Name, Fruit=None, XMLStack=None):
self.Name = XMLStack.UniqueID("Color", Name, self, XMLStack)
self.Fruit = XMLStack.ReferenceID(Fruit, XMLStack)
class Elements:
ChildSpec = XMLObject.ChildClass({"Fruit": XMLObject.StdChild(Fruit,
"Fruit", "List"), "Color": XMLObject.StdChild(Color, "Color", "List")},
"((<Fruit>) | (<Color>))*")
def __init__(self, XMLStack):
self.Fruit = []
self.Color = []
>>> import XMLObject, elements
>>> Elements = XMLObject.Parse("elements.xml", "Elements", elements.Elements)
>>> str(Elements.Color[0].Name)
'red'
>>> str(Elements.Color[1].Name)
'orange'
>>> str(Elements.Color[1].Fruit)
'orange'
>>> Elements.Color[1].Fruit.__class__
<class XMLObject.ReferenceID at 0x009832D0>
>>> Elements.Color[1].Fruit("Fruit").__class__
<class elements.Fruit at 0x009830F0>
>>> Elements.Color[1].Fruit("Fruit").Size
'medium'As you can see above, Color[1] is the Color "orange". This Color has been cross-referenced back to the Fruit "orange". As before, we can follow this cross-referencing by calling the ReferenceID instance as if it were a function, but this time we must pass a tag type. If we did not, then we couldn't be sure if the ReferenceID would return the Fruit "orange"... or the Color.
Example 5.3. Searching a Stack Instance
Finding a specific element in an XML document can be a pretty tiresome process of searches and sub-searches, but if that element is uniquely identified, then finding it is a snap with XMLObject.
Consider the following, order status data:
<Customers>
<Customer Name="Joe Blow">
<Order ID="Z98212" Status="shipped" />
</Customer>
<Customer Name="Gre7g Luterman">
<Order ID="H67921" Status="shipped" />
<Order ID="M26611" Status="lost" />
</Customer>
</Customers>
import XMLObject
class Order:
ChildSpec = XMLObject.ChildClass({}, "")
def __init__(self, ID, Status=None, XMLStack=None):
self._root = XMLStack[-1]
self._parent = XMLStack[0]
self.Status = Status
self.ID = XMLStack.UniqueID("Order", ID, self, XMLStack)
class Customer:
ChildSpec = XMLObject.ChildClass({"Order": XMLObject.StdChild(Order,
"Order", "Dict", Key="ID")}, "(<Order>)*")
def __init__(self, Name, XMLStack=None):
self.Name = Name
self.Order = {}
class Customers:
ChildSpec = XMLObject.ChildClass({"Customer": XMLObject.StdChild(Customer,
"Customer", "Dict", Key="Name")}, "(<Customer>)*")
def __init__(self, XMLStack=None):
self.Customer = {}
Suppose we wanted to find out what happened to order number "M26611". Without taking advantage of the UniqueID class, we would need to do a has_key on each Customer to first find out which customer had that order number, and then look at the order number itself to check the status. That isn't terribly difficult in this simple example because the Orders are only one level down from Customer. Just imagine the extra work if they were 10 levels down!
>>> import XMLObject, customers
>>> Customers = XMLObject.Parse("customers.xml", "Customers",
... customers.Customers)
>>> Matches = filter(lambda Customer: Customer.Order.has_key("M26611"),
... Customers.Customer.values())
>>> len(Matches)
1
>>> Matches[0].Name
'Gre7g Luterman'
>>> Matches[0].Order["M26611"].Status
'lost'
As I mentioned in the Introduction, I don't like using filter and lambda functions this way. The resulting code is nice and compact, but not particularly readible or maintainable. If your code looks like the above, you might want to rethink it.
If we, instead, instantiate our own Stack, then we can use it to look up UniqueIDs:
>>> import XMLObject, customers
>>> Stack = XMLObject.Stack()
>>> Customers = XMLObject.Parse("customers.xml", "Customers",
... customers.Customers, Stack)
>>> Stack("M26611").Status
'lost'
>>> Stack("M26611")._parent.Name
'Gre7g Luterman'
Symbols
- _parent, Special Attributes
- _root, Special Attributes
- __repr__, Outputting XML
A
- ASCII, Unicode and ASCII Strings
- attributes
- (required), XML Attributes
- constraining, Constraining XML Attributes
- named, XML Attributes
- special, The XMLObjApp Application, Special Attributes, Preferences...
- XML, The XMLObjApp Application, XML Attributes
B
- binary install (see install, binary)
- browser, Preferences...
C
- ChildClass, XMLObject -- XML to Object Conversion
- children, The XMLObjApp Application, VCD Strings, _end_init Constructor Completion
- ChildSpec, XMLObject -- XML to Object Conversion
- class
- parent (see parent class)
- class menu (see menu, class)
- class name (see name, class)
- column, Preferences...
- constraining (see attributes, constraining)
D
- delimiter, Configuring a #PCDATA Child Type
- dialog
- success, Sanity Test
- Dict, Configuring a Typical Child Type, XMLObject -- XML to Object Conversion
- do not modify, Setting a class' Parent
- document, Is XMLObject a good fit for my application?
- download, Downloading XMLObject
E
- editing, Setting a class' Parent
- _end_init, _end_init Constructor Completion
- errors, Sanity Test
- Exact, Configuring a #PCDATA Child Type , Configuring an <XML> Child Type, XMLObject -- XML to Object Conversion
- expression
- regular (see regular expression)
F
- File
- Close, Saving and Loading
- Import XML..., Import XML..., Preferences...
- Open, Saving and Loading
- Preferences..., Preferences...
- Quit, File->Quit
- Sanity Test, Saving and Loading
- Save, Saving and Loading
- Save As..., Saving and Loading
- file
- list, Preferences...
- File menu (see menu, File)
I
- indent, Preferences...
- __init__, Setting a class' Parent, _end_init Constructor Completion
- install, Installing XMLObject
- binary, XMLObject Module, XMLObjApp Application
- source, XMLObject Module, XMLObjApp Application
M
- menu
- class, Classes
- File, Saving and Loading
N
- name
- class, The XMLObjApp Application, Classes
O
- output, Outputting XML
P
- parent class, Classes, Setting a class' Parent
- Parse, Introduction, XMLObject -- XML to Object Conversion
- #PCDATA pseudo-tag (see pseudo-tag, #PCDATA)
- PCDATAChild, XMLObject -- XML to Object Conversion
- prefixes, Where is XMLObject headed?
- pseudo-tag
- pyRXP, Introduction, Is XMLObject a good fit for my application? , Unicode and ASCII Strings
R
- reduce, Configuring a Typical Child Type, _end_init Constructor Completion, XMLObject -- XML to Object Conversion
- ReferenceID, UniqueID and ReferenceID, Object Interface
- regular expression, The XMLObjApp Application, VCD Strings
- required attributes (see attributes, (required))
- root, Classes
S
- sanity test (see test, sanity)
- Single, Configuring a Typical Child Type, XMLObject -- XML to Object Conversion
- source install (see install, source)
- SourceForge, Downloading XMLObject
- space
- spaces, Preferences...
- special attributes (see attributes, special)
- Split, Configuring a #PCDATA Child Type , XMLObject -- XML to Object Conversion
- Split-Strip, Configuring a #PCDATA Child Type , XMLObject -- XML to Object Conversion
- Stack, XMLObject -- XML to Object Conversion, Object Interface
- StdChild, XMLObject -- XML to Object Conversion
- Strip, Configuring a #PCDATA Child Type , Configuring an <XML> Child Type, XMLObject -- XML to Object Conversion
- Strip-Split, Configuring a #PCDATA Child Type , XMLObject -- XML to Object Conversion
- Strip-Split-Strip, Configuring a #PCDATA Child Type , XMLObject -- XML to Object Conversion
- success (see dialog, success)
T
- tabs, Preferences...
- test
- sanity, Sanity Test, Preferences...
U
- unicode, Unicode and ASCII Strings
- unique identifiers, Introduction, Is XMLObject a good fit for my application?
- UniqueID, UniqueID and ReferenceID, Object Interface
V
- valid children definition (see VCD)
- validation, Is XMLObject a good fit for my application?
- VCD, VCD Strings, XMLObject -- XML to Object Conversion
W
- warnings, Sanity Test
- white-space (see space, white)
- wrap, Preferences...
X
- XML attributes (see attributes, XML)
- <XML> pseudo-tag (see pseudo-tag, <XML>)
- xml.dom, Introduction
- xml.sax, Introduction, Is XMLObject a good fit for my application? , Unicode and ASCII Strings
- XMLChild, XMLObject -- XML to Object Conversion
- XMLObjApp, The XMLObjApp Application
- XMLStructError, XMLObject -- XML to Object Conversion